协同过滤
协同过滤(Collaborative filtering, CF)及其变体是最常用的推荐算法之一。即使数据科学的新手也可以用它来构建自己的个人电影推荐系统,起码可以写在简历上。
我们想给用户推荐东西,最合乎逻辑方法是找到具有相似兴趣的人,分析他们的行为,并向用户推荐相同的项目。另一种方法是看看用于以前买的商品,然后给他们推荐相似的。
CF有两种基本方法:基于用户的协同过滤和基于项目的协同过滤。
无论哪种方法,推荐引擎有两个步骤:
- 了解数据库中有多少用户/项目与给定的用户/项目相似。
- 考虑到与它类似的用户/项目的总权重,评估其他用户/项目,来预测你会给该产品用户的打分。
“最相似”在算法中是什么意思?
我们有每个用户的偏好向量(矩阵R的行),和每个产品的用户评分向量(矩阵R的列),如下图所示。
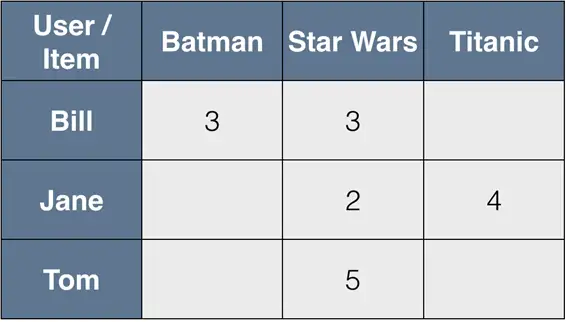
首先,我们只留下两个向量的值都已知的元素。
例如我们想比较Bill和Jane,已知比尔没有看泰坦尼克号,Jane没看过蝙蝠侠,于是,我们只能通过星战来衡量他们的相似度了。谁没看过星球大战呢是吧?
测量相似度的最流行方法是余弦相似性或用户/项目向量之间的相关性。最后一步,是根据相似度用加权算术平均值填充表中的空单元格。
矩阵分解
这是一个非常优雅的推荐算法,因为当涉及到矩阵分解时,我们通常不会太多地去思考哪些项目将停留在所得到矩阵的列和行中。但是使用这个推荐引擎,我们清楚地看到,u是第i个用户的兴趣向量,v是第j个电影的参数向量。
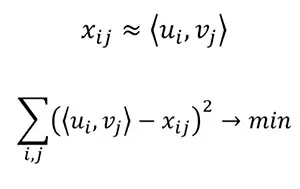
所以我们可以用u和v的点积来估算x(第i个用户对第j个电影的评分)。我们用已知的分数构建这些向量,并使用它们来预测未知的得分。